Node在选型时决定在V8引擎之上构建,它和浏览器类似,运行在单个进程的单个线程上。好处是:程序状态是单一的,在没有多线程的情况下没有锁、线程同步问题,操作系统在调度时也因为较少上下文的切换,可以很好的提高CPU的使用率。
同时带来两个缺点:
- CPU利用率
- 进程的健壮性
服务器的变迁
同步➡复制进程➡多线程➡事件驱动
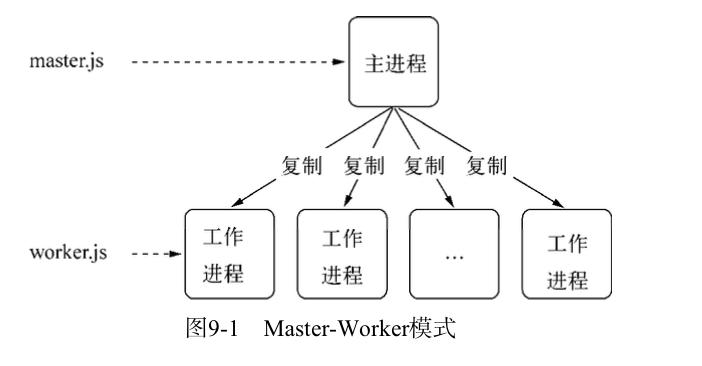
多进程架构
上图是著名的Master-Worker模式,又称主从模式。主进程不负责具体的业务处理,而是负责调度或管理工作进程,工作进程负责具体的业务处理。
创建子进程
child_process模块提供了4个方法用于创建进程:
spawn(): 启动一个子进程来执行命令exec(): 启动一个子进程来执行命令,与spawn()不同的是其接口不同,它有一个回调函数获知子进程的状况。execFile(): 启动一个子进程来执行可执行文件fork(): 与spawn()类似,不同点在于它创建的Node的子进程只需指定要执行的javascript文件模块即可。

可执行文件:可以直接执行的文件,如果是javascript文件,它的首行内容必须添加如下代码
1 | #!/usr/bin/env node |
进程间通信
在Master-Worker模式中,要实现主进程管理工作和调度工作进程的功能,需要主进程和工作进程之间的通信。对于child_process模块,创建好了子进程,然后与父子进程间通信是十分容易的。
子进程对象则由send()方法实现主进程向子进程发送数据,message事件实现收听子进程发来的数据。通过消息传递内容,而不是共享或直接操作相关资源,这是较为轻量和无依赖的做法。
1 | // parent.js |
进程间通信原理
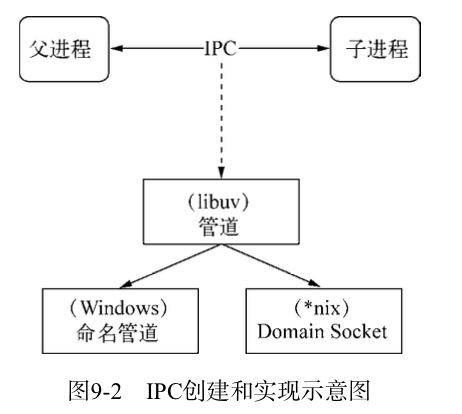
IPC的全称是Inter-Process Communication, 即进程间通信。进程间通信的目的是为了让不同的进程能够互相访问资源并进行协调工作。Node实现IPC通道由libuc实现。示意图如下
父进程在实际创建子进程之前,会创建IPC通道并监听它,然后才真正创建子进程,并通过环境变量(NODE_CHANNEL_FD)告诉子进程这个IPC通道的文件描述符。子进程在启动的过程中,根据文件描述符去连接这个已存在的IPC通道,从而完成父子进程之间的连接。下图为IPC管道的步骤示意图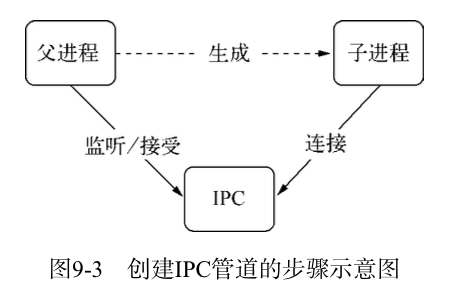
句柄传递
什么是句柄?句柄是一种可以用来标识资源的引用,它的内部包含了指向对象的文件描述符。比如句柄可以用来标识一个服务器端socket对象、一个客户端socket对象、一个UDP套接字、一个管道。
主进程接收到socket请求后,将这个socket直接发送给工作进程,而不是重新与工作进程之间建立新的socket连接来转发数据。主进程代码如下:
1 | // parent.js |
子进程代码如下:
1 | process.on('message', function(m, server){ |
测试的结果是每次出现的结果都可能不同,结果可能被父进程处理,也可能被不同的子进程处理。并且这是在TCP层面上完成的事情,我们尝试转化到HTTP层面来试试。对于主进程,将服务器句柄发送给子进程之后就可以关掉服务器的监听,让子进程来处理。父进程改动如下:
1 | // parent.js |
子进程改动如下:
1 | var http = require('http'); |
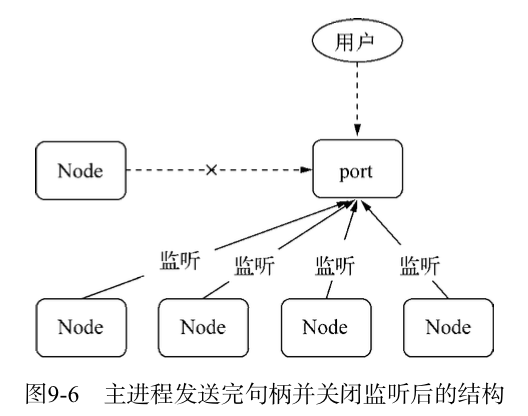
这样一来,所有的请求都是由子进程处理。整个过程中,服务的过程发生了一次改变,如图
主进程发生完句柄并关闭监听之后,成为如下图结构

1. 句柄发生与还原
句柄发送跟我们直接将服务器对象发送给子进程有没有差别?
它是否真的将服务器对象发送给子进程?
为什么它可以发送到多个子进程中?
发送给子进程为什么父进程中还存在这个对象?
目前子进程对象send()方法可以发送的句柄类型包括如下
- net.Socket TCP套接字
- net.Server TCP服务器,任意建立在TCP服务上的应用层服务都可以享受到它带来的好处
- net.Native C++层面的TCP套接字或IPC管道
- dgram.Socket UDP套接字
- dgram.native C++层面的UDP套接字
send()方法在将消息发送到IPC管道前,将消息组装成两个对象,一个参数是handle,另一个是message。
以发送的TCP服务器句柄为例,子进程收到消息后的还原过程如下:

1 | function(message ,handle, emit) { |
2. 端口共同监听
为何通过发送句柄后,多个进程可以监听到相同的端口而不引起EADDRINUSE(端口占用)异常?
因为独立启动的进程中,TCP服务器端socket套接字的文件描述符并不相同,导致监听到相同的端口时会抛出异常。但对于sned()发送的句柄还原出来的服务而言,它们的文件描述符是相同的,所以监听相同的端口不会引起异常。
多个应用监听相同的端口时,文件描述符同一时间只能被某个进程所用。换言之,网络请求向服务器发送时,只有一个幸运的进程能够抢到连接,也就是说只有它能为这个请求进行服务。
集群稳定之路
搭建好Node集群,充分利用多核CPU资源,还有一些细节需要考虑:
- 性能问题
- 多个工作进程的存活状态管理
- 工作进程的平滑启动
- 配置或者静态数据的动态重新载入
- 其他细节
虽然我们创建了很多工作进程,但每个工作进程依然是在单线程上执行,它的稳定性还不能得到完全的保障。我们需要建立一个健全的机制来保障Node应用的健壮性。
进程事件
子进程除了message事件外,Node还有如下事件:
- error: 当子进程无法复制创建、无法被杀死、无法发送消息时会触发该事件。
- exit: 子进程退出时触发该事件,子进程如果是正常退出,这个事件当第一个参数为退出码,否则为null。如果进程是通过
kill()方法被杀死,会得到第二个参数,它表示杀死进程时的信号。 - close: 在子进程的标准输入输出流中止时触发该事件,参数与exit相同。
- disconnect: 在父进程或子进程调用
disconnect()方法时触发该事件,在调用该方法时将关闭监听IPC通道
上述这些事件是父进程能监听到的与子进程相关的事件。除了send()外,还能通过kill()方法给子进程发送消息。kill()方法并不能真正将通过IPC相连的子进程杀死,它只是给子进程发送了一个系统信号。默认情况下,父进程将通过kill()方法给子进程发送一个SIGTERM信号。它与进程默认的kill()方法类似。如下:
1 | // 子进程 |
它们一个发给子进程,一个发给目标进程。在POSIX标准中,有一套完备的信号系统,Node提供了这些信号对应的信号事件,每个进程都可以监听这些信号事件。这些信号事件是用来通知进程的,每个信号事件有不同的含义,进程在收到响应信号时,应当做出约定的行为。如SIGTERM是软件终止信号,进程收到该信号时应当退出。示例代码如下:
1 | process.on('SIGTERM', function(){ |
自动重启
有了父子进程之间的相关事件之后,就可以在这些关系之间创建出需要的机制了。比如重新启动一个工作进程来继续服务: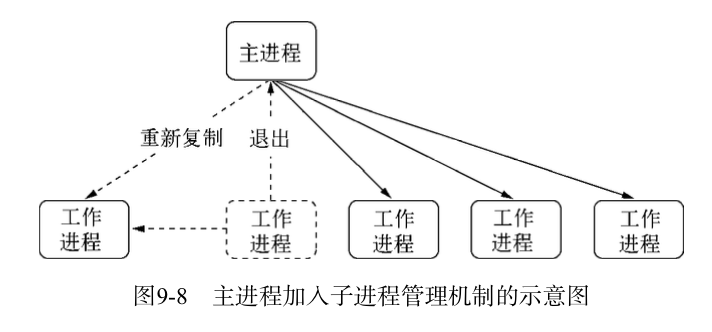
1 | // master.js |
在这个场景中我们主动杀死一个进程,在实际业务中,可能有隐藏的bug导致工作进程退出,我们需要仔细处理这种异常:
1 | // worker.js |
上述代码的处理流程是,一旦有未捕获的异常出现,工作进程就会立即停止接收新的连接;当所有连接断开后,退出进程。主进程在侦听到工作进程的exit后,将会立即启动新的进程服务,一次保证整个集群中总有进程在为用户服务的。
1. 自杀信号
上述代码存在的问题是要等到已有的所有连接断开后进程才退出,在极端情况下,所有工作进程都停止接收新的连接,全处在等待退出的状态,但在等到进程完全退出才重启的过程中,所有新来的请求可能存在没有工作进程为新用户服务的情景,这会丢掉大部分请求。
为此需要改进这个过程,不能等到工作进程退出后才重启新的工作进程。当然也不能保留退出进程,因为这样会导致已连接的用户直接断开。于是我们在退出的流程中增加一个自杀(suicide)信号。工作进程在得知要退出时,向主进程发送一个自杀信号,然后才停止接收新的连接,当所有连接断开后才退出。主进程在接收到自杀信号后,立即创建新的工作进程服务。
1 | // worker.js |
主进程将重启工作进程的任务,从exit事件的处理函数中转移到message事件的处理函数中,如下所示:
1 | // master.js |
至此我们完成了进程的平滑重启。一旦有异常出现。主进程会创建新的工作进程来为用户服务,旧的进程一旦处理完已有连接就自动断开。整个过程使得我们的应用的稳定性和健壮性大大提高。示意图如下: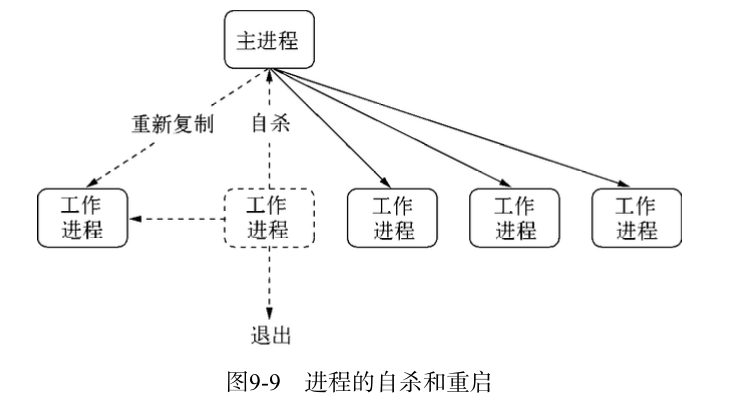
这里存在问题的是有可能我们的连接是长连接,不是HTTP服务的这种短连接,等待长连接断开可能需要较久的时间。为此为已有连接的断开设置一个超时时间是必要的,在限定时间里强制退出的设置如下所示:
1 | // worker.js |
2. 限量重启
通过自杀信号告知主进程可以使得新连接总是有进程服务,但是依然还是有极端情况。工作进程不能无限地被重启,如果启动的过程中发送了错误,或者启动后接到连接就收到错误,会导致工作进程被频繁重启,这种频繁重启不属于我们捕捉未知异常的情况,因为这种短时间内频繁重启已经不符合预期的设置,极有可能是程序编写的错误。
为了消除这种无意义的重启,在满足一定规则的限制下,不应当反复重启。在单位时间内规定只能重启多少次,超过限制就触发giveup事件,告知放弃重启工作进程这个重要事件。
为了完成限量重启的统计,我们引入一个队列来做标记,在每次重启工作进程之间进行打点并判断重启是否太过频繁,如下:
1 | // master.js |
giveup事件是比uncaughtException更严重的异常事件。uncaughtException只代表集群中某个工作进程退出,在整体性保证下,不会出现用户得不到服务的情况,但是这个giveup事件则表示集群中没有任何进程服务了,十分危险。
负载均衡
Node中的策略是Round-Robin,又叫轮叫调度。
状态共享
Node进程中不宜存放太多数据,因为它会加重垃圾回收的负担,进而影响性能。同时,Node也不允许多个进程之间共享数据。我们需要一种方案和机制来实现数据在多个进程之间的共享。
解决数据共享最直接、简单的方式是通过第三方来进行数据存储,同时还需要状态同步的机制:定时轮询、主动通知
Cluster模块
前文介绍了child_process模块中的大多数细节,以及如何通过这个模块构建强大的单机集群。但在Node0.8版本引入了cluster模块,用以解决多核CPU的利用率问题,同时也提供了较完善的API。
本章开头提到的创建Node进程集群,cluster实现起来也很轻松,如下:
1 | // cluster.js |
在进程中判断是主进程还是工作进程,主要取决于环境变量中是否有NODE_UNIOE_ID,,如下所示:
1 | cluster.isWorker = ('NODE_UNIOE_ID' in process.env); |
建议使用cluster.setupMaster(),将主进程和工作进程从代码上完全剥离,如图send()方法看起来直接将服务器从主进程发送到子进程那样神奇,剥离代码之后,甚至感觉不到主进程中有任何服务器相关代码。
Cluster工作原理
事实上cluster模块就是child_process和net模块到组合应用。cluster启动时,它会在内部启动TCP服务器,在cluster.fork()子进程时,将这个TCP服务器socket的文件描述符发送给工作进程。如果进程是通过cluster.fork()复制出来,那么它的环境变量就存在NODE_UNIOD_ID,如果工作进程中存在listen()侦听网络端口的调用,它将拿到该文件描述符,通过SO_REUSEADDR端口重用,从而实现多个子进程共享端口。对于普通方式启动的进程,则不存在文件描述符传递共享等事情。
Cluster事件
对于健壮性处理,cluster模块也暴露了相当多的事件
- fork: 复制一个工作进程后触发该事件
- online: 复制好一个工作进程后,工作进程主动发送一条online消息给主进程,主进程收到消息后,触发该事件
- listening: 工作进程中调用
listen()(共享了服务器端socket)后,发送一条listening消息给主进程,主进程收到消息后,触发该事件。 - disconnect: 主进程和工作进程之间IPC通道断开后触发该事件
- exit: 有工作进程退出时触发该事件
- setup:
cluster.stepMaster()执行后触发该事件
总结
在实际复杂业务中,我们可能要启动很多子进程来处理任务,结构甚至远比主从模式复杂,但是每个子进程应当是简单到只做好一件事,然后通过进程间通信技术将它们连接起来。这是符合Unix的设计理念,每个进程只做一件事,并做好一件事,将复杂分解为简单,将简单组合成强大。
